우리 서버에서 Spring Session을 사용하고 있는데, 부끄럽지만 여태 그 이유를 제대로 모르고 있었다.
오늘 선배님이 던진 질문을 계기로 조금이나마 공부해봤다.
Spring Session 개요
Spring Session은 왜 사용하는 걸까? Baeldung의 Overview에 간략한 설명이 나와 있다.
Spring Session has the simple goal of free up session management from the limitations of the HTTP session stored in the server. The solution makes it easy to share session data between services in the cloud without being tied to a single container (i.e. Tomcat). Additionally, it supports multiple sessions in the same browser and sending sessions in a header.
Spring Session의 목적은 단순하다. Spring Session은 서버에 저장되는 HTTP 세션의 한계점을 극복하여 세션 관리하기 위해 사용한다.
- 클라우드 상에서 운영되는 서버(
clustered sessions) 사이에서 Session을 공유할 수 있도록 지원한다. (즉, Tomcat과 같은 싱글 컨테이너로 묶지 않아도 된다.) - 같은 브라우저에서 여러 세션을 관리할 수 있도록 지원한다.
- 세션을 헤더에 보낼 수 있게 지원한다.
Spring Session 공식 문서에 따르면, Spring Session은 다음의 요소들과 완벽하게 통합(transparent integration)할 수 있도록 지원한다. (별다른 구현 없이 알아서 Spring Session으로 통합 가능하다는 말로 보인다.)
HttpSession: session IDs를 제공하여HttpSession을 container-neutral way로 대체해준다. (한 컨테이너에 종속되지 않게 바꾸어 준다는 뜻으로 보인다.)WebSocket:WebSocket메세지를 받을 때,HttpSession가 남아 있을 수 있게(keep alive) 해준다.WebSession: Spring WebFlux의WebSession을 container-neutral way로 대체해준다.
우리 서비스는 쿠버네티스에서 운영하고 있다. 그러다 보니 pod 사이에서 세션 공유가 필요한데, Spring Session을 통해 이를 해결하고 있다.
설정 방법
본 글이 설정하고 사용하는 방법을 설명하기 위한 글은 아니지만, 간단하게 남겨본다. 이미 datasource 관련 설정은 되어 있다는 가정 하에 다음을 추가한다.
Spring Session은 JDBC, Gemfire, MongoDB, Redis 등을 통해 데이터 관리가 가능한데, 우리는 JDBC를 이용하고 있다.
build.gradle 파일에 다음의 의존성을 추가하고,
compile('org.springframework.session:spring-session-jdbc')
application.yml에 다음과 같은 설정을 추가한다. (session.timeout, spring.session.jdbc.table-name 등의 세부 사항을 설정할 수도 있다. 자세한 사항은 문서 참조!)
spring.session.store-type: jdbc
Spring Session 설정 후 애플리케이션을 구동하면 다음의 테이블이 자동으로 생성된다.
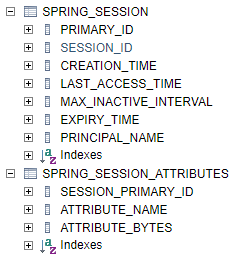
사용 예시
앞서 설명했듯이, Spring Session은 HttpSession과 완벽하게 통합된다.
HttpSession의 setAttribute(String name, Object value)메소드로 attribute를 저장하면, 그 attribute는 DB 안의 SPRING_SESSION, SPRING_SESSION_ATTRIBUTES 테이블에 저장된다.
setAttribute(String name, Object value)의 name은 SPRING_SESSION_ATTRIBUTES의 ATTRIBUTE_NAME 칼럼에, value는 ATTRIBUTE_BYTES에 저장된다.
이처럼 세션 데이터가 DB에 저장되기 때문에 클러스터 간에 데이터 공유가 가능해진다. 그리고 이 만료 시간(EXPIRY_TIME) 알아서 관리해주어, 데이터를 따로 지울 필요도 없다.
얕게 나마 공부해봤는데, 왜 사용하는지 명확하게 알게 되어 기분이 좋다😉.
참고자료
본문 속 링크 참조